Concepts
How it works
Our platform covers the whole digital R&D process, from initial data creation or import to
complex analysis to final reports. It doesn't make any assumptions about the structure of
your data and thus allows you to stay flexible. Work inside the platform is structured in a
way that represents work done in research projects.
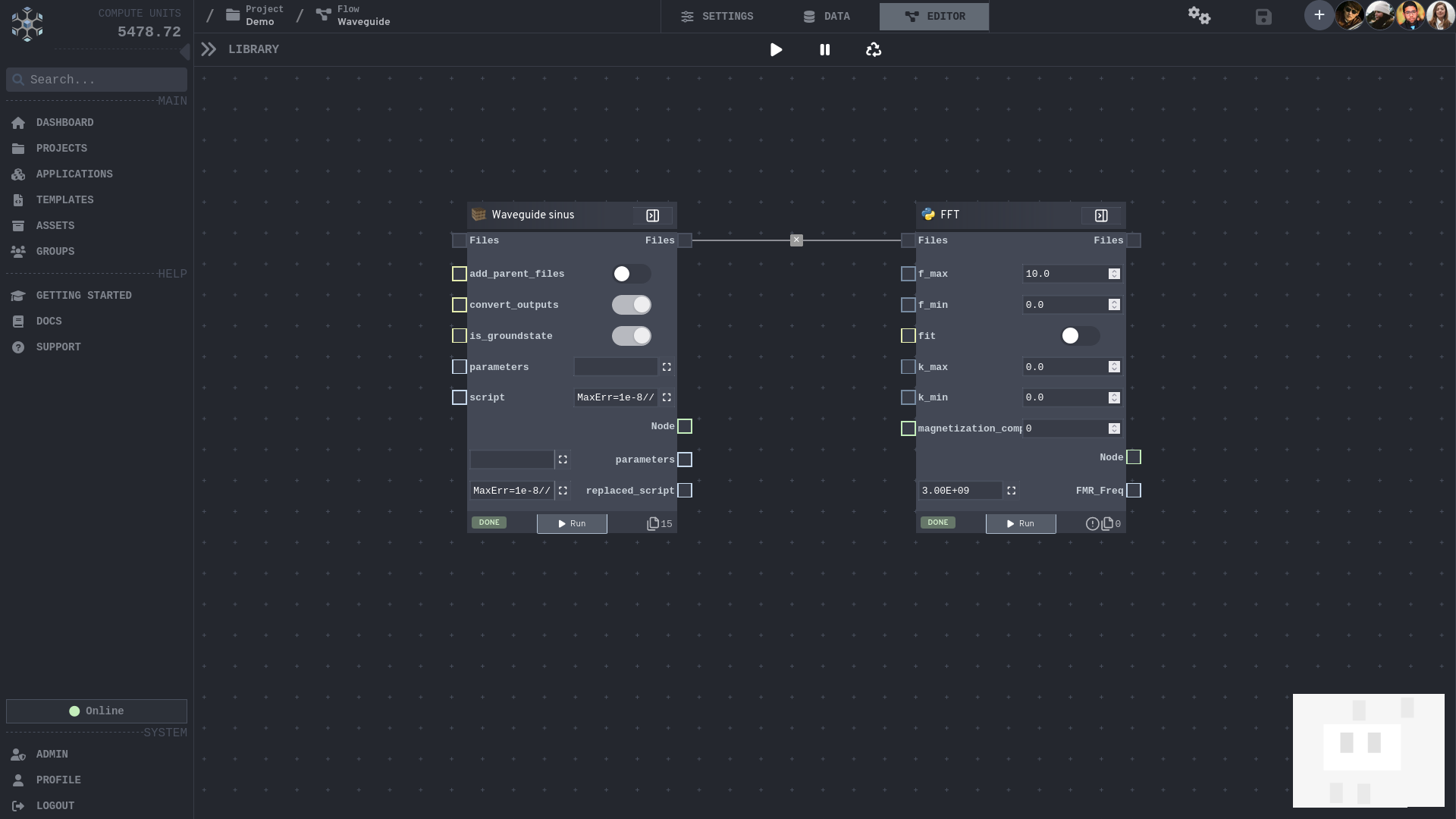
Flows
Flows represent sequences of nodes. They support large-scale process graphs spanning
thousands of individual nodes. Our platform offers versatile tools to build these,
from a low-code editor to programmatic creation through an API or a CLI tool. For
example, nodes can dynamically produce children, extending the process graph based
on your own logic. This can be useful, e.g. to create a parametric sweep where each
node processes a set of parameters. Through the topology of the process graph, our
engine determines which nodes can be executed in parallel or sequentially.
Therefore, everyone is able to benefit from distributed computing without much prior
knowledge about it. Also, flows can be reused as templates, making automating
reoccurring work a breeze.
Flow-based programming
Templates
Distributed computing
Low code
Real-time collaboration
Notes and reports
Nodes
Nodes are the smallest building blocks they contain everything needed to run a single
job. Single nodes can be connected to complex workflows spanning multiple applications.
From bare metal to cloud VMs
Nodes can be scheduled and executed on bare metal machines or VMs located in a cloud or
data-center. When creating a node, a description of the required hardware resources like
memory, CPU cores or a GPU can be provided. They will only reserve and block the
required resources on the executing machine. Unused resources can then be provided to
another node, making sure that the available hardware is utilized to the fullest.
Container as basis for applications
Container technology has become
an ubiquitous tool in modern software development. Applications and software can be packaged
into a container to make them easily portable. It allows to exactly reproduce the output
of a program as the complete execution environment can be controlled in this way. Time consuming
installation or even compilation steps can be completely skipped once a container is available,
making it easy to work in a team with the same software.
User defined code
Once a container is running on a machine, code provided by the user will be executed.
This can be anything from simple bash scripts to sophisticated data analysis with Python
or using CLI tools to e.g. run a simulation. A built-in IDE makes it easy to quickly
iterate on this code and fix any errors that may arise during development.
Alternatively, complete nodes can also be shared with colleagues so that also non-programmers can use the platform via the low-code editor.
Alternatively, complete nodes can also be shared with colleagues so that also non-programmers can use the platform via the low-code editor.
The data layer
Inputs from prior nodes is fed into the node during startup. Also, files from prior
nodes can be dynamically accessed when necessary. During execution, all log output is
directly collected and displayed to the user. Also, variable outputs are collected upon
successful execution. Nodes can also work with a central storage, making it easy to save
any generated files for later use. Also, nodes can directly produce an optional report
for human analysis. They can contain interactive graphs, markdown or html and are
displayed directly in the GUI. Our built-in search engine allows to quickly query this
produced data.
Data Management
As the data landscape in the research process is quite diverse, it's hard to enforce any
specific format. Software might have their own specialized data formats or you might
need to work with multi-dimensional data. That is why we support plain files as first
class citizen in the platform and offer tooling to make it as easy as possible to work
with them.
Track where your datasets were reused through the data graph.
Track where your datasets were reused through the data graph.
Import and export
Globally unique DOIs
Tracked metadata
Access control
Automatic compression
Checksums
The Data Graph
Data still often times come as files, be it from laboratory software or a simulation
program. When working with files, our platform tracks all accesses and usages. Further
processing is always linked to the corresponding raw data. Everything can be backtracked
to the initial creation or import of the data. This makes sure that all data has rich
context that can help to understand it, even in years to come. They are always attached
to Nodes, so that even the involved application and
code is directly accessible.
Subscribe to our newsletter
Stay connected
By submitting this form, you acknowledge and agree that Aithericon will process your
personal information in accordance with the
Privacy Policy.
You can unsubscribe at any time by clicking the link in the footer of our emails.